

Lo scopo fondamentale di una rete è connettere utenti e applicazioni, chi produce dati e chi li consuma con lo storage. Pertanto, la prima caratteristica basilare di una rete è la capacità di ottimizzare l’accesso ai servizi agli endpoint che li utilizzano. A questo scopo dobbiamo considerare (tra le altre cose) questi principi:
- prestazioni – che la rete sia abbastanza veloce da supportare l’uso dell’applicazione;
- capacità – che la larghezza di banda a disposizione sia sufficiente;
- ridondanza – in caso di guasto, che la rete sia in grado di aggirarlo.
È tenendo a mente questi principi che progettiamo le nostre reti.
Documentare la propria rete nel Mondo reale
Tuttavia, accade che la crescita organica nel vostro ambiente IT porti al mancato rispetto dei principi di progettazione originali. Occorre pertanto modificare la rete, perché soddisfi un nuovo requisito e bisogna farlo velocemente! Per questo si apporta una modifica alla rete che sì, offre una soluzione, ma compromette i principi di progettazione originali.
Spesso ciò significa collegare un nuovo link a un nuovo dispositivo che non ha sufficiente capacità, velocità o resilienza. Oppure qualche invisibile problema di configurazione impedisce ai link ridondanti di essere pronti all’uso. Quando si verifica tale problema, fornitore e utenti del servizio ne soffrono, perché i principi stabiliti per ottimizzare la fruizione non sono stati rispettati e i sistemi vanno in crisi. A questo punto non resta che identificare il motivo per cui le cose non hanno funzionato.
Da dove iniziare?
Quando avete costruito la vostra rete, i diagrammi e i documenti di progettazione erano ottimali, ma nessuno li ha aggiornati nel tempo. Pertanto dovete iniziare da dove essi terminano e:
- eseguire la scansione della rete manualmente hop-by-hop;
- fare uno schema di ogni nodo, collegamento, indirizzo MAC e IP mentre procedete;
- trasferire il tutto su Visio.
A questo punto, con il team di rete, occorre individuare i singoli points of failure e capire come risolverli. Ricordate che potrebbero non essere immediatamente evidenti nella topologia fisica, ma piuttosto nella configurazione logica!
Lasciatelo fare a IP Fabric
Ogni volta che IP Fabric esegue uno snapshot, rileva la topologia di rete dal livello fisico verso l’alto. Facendo clic sul menù Diagrams/Site Diagrams si visualizza la topologia:

Dopo aver disattivato i Layer 1 e 3 per ottenere maggiore chiarezza, selezionate nelle Opzioni Single Points of Failure, IP Fabric li evidenzia contornandoli in rosso:

IP Fabric può analizzare e interpretare le relazioni tra i dispositivi sia a monte che a valle. In questo caso, gli switch vengono visualizzati come SPOF, perché per alcuni switch di accesso sono gli unici dispositivi a monte.
Come abbiamo visto, l’efficace visualizzazione di IP Fabric ci aiuta a valutare i problemi nelle topologie, ma esistono visualizzazioni alternative della rete altrettanto potenti. Ad esempio, è possibile controllare un percorso simulato tra host per singoli points of failure.
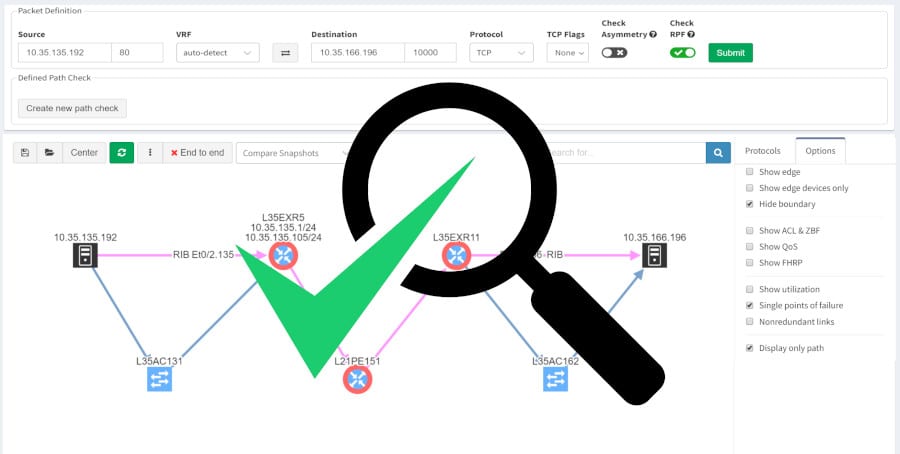
Selezionando Diagrams|End-to-end path i dispositivi non ridondanti si possono evidenziare lungo il path, dopo aver inviato gli IP di origine e di destinazione.

Altra funzione leggermente diversa è quella di evidenziare i link non ridondanti, mostrando dove è presente una stretta dipendenza dal link per garantire un percorso end-to-end tra gli host.

In questo modo IP Fabric fa risparmiare enormi quantità di tempo e fatica individuando al posto vostro i singoli points of failure nella topologia di rete. Ora potete rimediare proattivamente prima che diventino un problema!
Se avete trovato utile questo articolo, continuate a seguire il nostro profilo LinkedIn o il Blog, dove pubblicheremo altri contenuti. Se desiderate vedere con i vostri occhi come IP Fabric può aiutarvi a gestire la vostra rete più efficacemente, contattateci visitando il nostro sito www.ipfabric.io.

{kind=link}